
💡 Thread Hierarchy

- 커널 함수가 호스트에서 호출될 때, 많은 수의 스레드가 생성됨
- 스레드 계층 구조는 스레드 블록과 그리드로 구성됨
- 어떤 스레드가 어떤 데이터를 처리할지 인덱싱을 해주는게 프로그래머가 해야할 역할임
- 그리드와 스레드 블록의 크기는 두 개의 built-in 변수를 이용하여 구할 수 있음
- gridDim:그리드 크기(그리드 내의 블록의 수), gridDim.x, gridDim.y, grindDim.z
- blockDim: 블록의 크기(블록 내의 스레드의 수), blockDim.x, blockDim.y, blockDim.z
- blockIdx: 그리드 내에서 블록 인덱스
- threadIdx: 블록 내에서 스레드 인덱스
- 데이터의 개수=스레드의 개수= 블록의 크기 * 그리드의 크기
- 나누어 떨어지지 않는 경우 스레드의 개수가 데이터 개수보다 조금 더 크도록 구성하면 됨
- 글로벌 인덱스 int idx = blockDim.x*blockIdx.x+threadIdx.x

💡 CUDA Kernel
- 커널 함수는 디바이스에서 실행되는 코드
- 커널 함수에서는 단일 스레드에 대한 계산을 정의하고 해당 스레드에 대한 데이터 접근을 정의
- 커널은 __global__ 선언 한정자를 사용하여 정의됨
- 커널 함수는 반드시 void return tyoe 이어야 함
- 커널 호출 시 그리드와 스레드 블록의 크기를 <<<>>>안에 지정, kernel_name<<<grid, block>>>(argument list);
- argument에 들어가는 변수들은 GPU에서 접근 가능한 메모리 영역에 있어야 함
- 커널 호출은 호스트 스레드에 대해 비동기적임 -> GPU한테 작업을 넘겨주고 CPU는 다음 줄로 넘어감
- cudaDeviceSynchronize 함수를 호출하여 결과를 갖는 작업에 대해 동기화를 진행해주어야 함
- 모든 작업이 끝난 뒤 프로그램을 종료하기 전에 cudaDeviceReset이라는 함수를 호출하여 할당했던 자원들을 해제해주고 synchronize 기능도 수행해주어야 함
#include <stdio.h>
__global__ void GPUKernel(int arg){
printf("Input Value (on GPU) = %d \n", arg);
}
int main(void){
printf("Call Kernel Function \n");
GPUKernel<<<1,1>>>(1);
GPUKernel<<<1,1>>>(2);
cudaDeviceSynchronize();
return 0;
}결과
Call Kernel Function
Input Value (on GPU) = 1
Input Value (on GPU) = 2
#include <stdio.h>
__host__ __device__ void Print(){
printf("Hello from Print()\n");
}
__global__ void Wrapper(){
Print();
}
int main(void){
Print();//from host
printf("===============\n");
Wrapper<<<1,5>>>();
cudaDeviceReset();
return 0;
}결과
Hello from Print()
===============
Hello from Print()
Hello from Print()
Hello from Print()
Hello from Print()
Hello from Print()💡 2차원

1차원일 때는 thred 개수만 주면 되지만, 2차원부터는 index 자체도 2차원으로 표현이 된다.
x하고 y는 독립적인 축이기 때문에 서로 영향을 주지 않으므로 독립적으로 처리해서 local index를 이용하여 x와 y에 대한 global index를 구하면 된다.
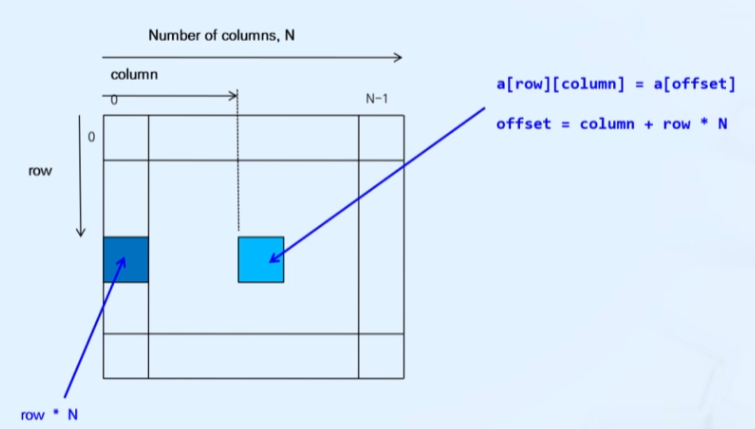
2차원 배열을 사용한 메모리는 계산 순서와 루프에 따라 캐시가 배열에 어긋나서 성능이 떨어질 수 있는데 이를 캐시 미스라고 한다. 그래서 캐시 미스를 사전에 차단하기 위해 메모리에서는 주로 1차원 array를 사용하며, row와 col을 통해서 1차원 상의 index를 구한다. index를 구하는 법은 밑의 코드 예제와 같다
__device__ int getGlobalIdx_2D(const int N){
int col = blockIdx.x*blockDim.x+thredIdx.x;
int row = blockIdx.y*blockDim.y+thredIdx.y;
int index = col+row*N;
return index;
}커널 함수를 호출할 때 그리드의 크기와 블록의 크기를 정해줘야 하는데 곱하기로 딱 떨어지지 않는 숫자인 경우에는 조금 더 큰 thread 개수를 발생시켜야 한다. 만약 thread 개수가 실제 데이터 개수보다 조금 많은 경우에는 데이터가 없는 thread가 생기게 되는데 이때 비어있는 thread에서 계산을 수행하면 잘못된 메모리 영역으로 접근을 해서 segmentation fault 에러가 발생하므로 예외 처리를 해주어야 한다. 예제는 밑의 코드이다.
template <int col> __global__ vpod AddMatOnGPU(float *A, float *B, float *C, int M, int N){
int idx_x=blockIdx.x*blockDim.x+threadIdx.x;
int idx_y=blockIdx.y*blockDim.y+threadIdx.y;
float (*pA)[col]=(float (*)[col])A;
float (*pB)[col]=(float (*)[col])B;
float (*pC)[col]=(float (*)[col])C;
if(idx_x<N && idx_y<M) pC[idx_y][idx_x] = pA[idx_y][idx_x]+pB[idx_y][idx_x];//예외 처리 부분
}강의
'CUDA' 카테고리의 다른 글
| GPU Architecture, CUDA Compiler (0) | 2024.02.14 |
|---|---|
| CUDA, 병렬 프로그래밍 (0) | 2024.02.13 |